
Managing state in programming is unavoidable. Software engineers constantly aim to limit its side effects to reduce accidental complexity. However, in the data space, managing state is not just unavoidable—it's the primary means to understanding the ever-changing world. Every time you transform data, alter your schema, or updates happen upstream you are manipulating the state of the data asset.
You can think of a data asset, similar to a river: it changes and evolves over time due to several factors, such as new data coming in, existing data being updated or deleted, the asset going through its own lifecycle – from developing, testing up to deploying and publishing – or upstream changes that have to be propagated downstream. With each such change, a new variation of the asset is created in the form of a table in the data warehouse and new metadata is created.
Data assets experience changes in state in three distinct ways.
The first is when new data comes in. Tables in your data warehouse act as specific snapshot in time of your data asset, capturing its state at a particular moment. While these snapshots remain unchanged, the actual data asset, similar to a flowing river, continually evolves and progresses with the influx of new data.

The second way a data asset changes state occurs during its development lifecycle. It moves through various stages, including planning, designing, materialization in the data warehouse, data testing, data contracts enforcement, deployment, publishing, and monitoring. Each of these stages results in a new metadata state for the data asset.

The third way data assets change state is through their interconnectedness. The output of each data asset is linked to the outputs of its upstream assets. Consequently, when an upstream asset undergoes an update, it requires corresponding updates in the downstream assets. This creates a ripple effect that propagates through the entire pipeline, affecting multiple assets at once.

A data asset is not just a table or a snapshot of the world at a specific time. A data asset is a collection of tightly coupled components such as code/config (git) state, data warehouse state, the set of tables materialized over time, and metadata, built as a single entity. A data asset exists to facilitate the end user understanding the world.
To encapsulate all of these components into a single logical unit, we introduce a new stateful and declarative approach of building and managing data assets, called Stateful Data Assets.
But before we deep dive into Stateful Data Assets, let's first explain what stateful and declarative mean and how they differ from their counterparts: stateless and imperative.
What is stateful?
Stateful is a term used to describe a system, or an object that retains information or “state” across interactions over time, from one operation to the next. This memory of past events can influence future operations.This is in contrast to stateless systems, which do not retain any information between interactions.
However, being stateful doesn't negate idempotency. In Y42, while a model's transformation logic is idempotent (consistently producing the same outcome regardless of how many times it's run), the model asset itself retains state, capturing its history and changes over time as new data flows in.
In the context of data engineering and pipelines, stateful refers to the fact that data assets can retain information across the different stages of the asset lifecycle, transformations, or over time. This stateful nature of data assets means that the output at any stage of the pipeline may be influenced by the accumulated state of the data up to that point.
To give an example, consider a data asset that accumulates records over time from various sources. When new data is integrated into the asset, a stateful system remembers the prior state of the asset, runs all tests and merges the new data appropriately in. Furthermore, since the system tracks all variations of the asset, if one of the tests fails, it can fallback to the previous successful run of the asset.

In contrast, in a stateless system, every time new data is added, the system would treat the asset as entirely new, without any reference to its prior state. This means it doesn't matter how many times a model has been run before, or even if it has ever been run; every execution is treated as if it's the first. A prime example of this is dbt. When rolling back code changes in such a stateless environment, the system wouldn’t have any knowledge of how the asset was physically materialized at any previous point in time.

What is declarative?
The declarative approach is about specifying what you want to achieve without necessarily detailing how to achieve it. You declare the desired outcomes, and the underlying system determines the steps to get there.
On the other hand, the imperative paradigm is about how you want to achieve a certain state by detailing the step-by-step process to achieve a desired outcome. As a user you have to provide direct instructions, where you specify every operation and the order in which they must be executed.
For data assets, the declarative approach translates to specifying the desired end state of the dataset, without explicitly telling the system how to get there. For instance, you might declare that you want a dataset that consolidates data from several sources, filters out irrelevant records, apply tests, and sorts the remainder by a specific criterion. That is the end state. The underlying system will then figure out the best way to materialize this request.

In contrast, in an imperative approach, you'd explicitly detail that first, you merge datasets A and B, then filter records with a specific attribute, followed by sorting the resultant set.

Benefits of working with stateful, declarative data assets
Merging the concepts of statefulness and declarativeness leads us to a medium where you can define the end state of how you want your data transformations to look like, what tests to pass, or who should have access to, without providing step-by-step instructions, coupled with a complete auditable trail derived from the rich metadata collected by Y42 at each stage.
This approach brings several advantages. Firstly, it offers abstraction. As a user, I don’t need to manage each step individually of building a data asset, allowing us to concentrate on broader data objectives. Then there’s standardization. As data warehouses become faster and more cost-efficient, the underlying system – Y42 – adapts and employs the best optimizations to achieve the desired outcomes without requiring users to rewrite their queries.
Simplicity is another benefit of working with stateful data assets. I can easily select the metadata state I want to roll back to or the version I want to merge into production, eliminating the need for the user to connect the right version of code with the data: wondering whether a code change was applied before or after a backup was taken, or if it's safe to restore from certain backups and to what state the code needs to rollback to. The stateful approach also means less maintenance, which in turn decreases the development cycles.
Moreover, the process is highly auditable. By tracking every code change and state transition of data and metadata, the entire process of building data assets becomes traceable and accountable. This is similar to the benefits of using Git for code, but it extends to the data as well – encompassing everything from how assets are materialized to deploying, publishing, or monitoring the state of an asset..
Lastly, in conjunction with Virtual Data Builds, we can instantly revert back to any previous state of the data asset efficiently through a view pointer swap with zero compute resources.
Understanding the structure of a data asset
A data asset is defined by key identifiers including its name, description, type, creation date, and others. It also encompasses links to its upstream dependencies, and includes materialization information, tests, and access control logic.
Below is a pseudocode representation of a data asset:
meta:
- name: dim_products
description: products dimension
owner: @octavian
type: [source or model]
columns:
- name: id
description: ..
tests:
- not_null
tags:
- PII
...
depends_on:
- name: stg_products
...
logic:
materialization_type: [dimension, SCD2]
materialization_logic: models/marts/sc/dim_products.sql
post_materialization_logic: models/marts/sc/dim_products_post.sql
test_logic:
- schema_tests: ..
- table_tests:
- volume_anomalies: ..
- freshness_anomalies: ..
acl_logic:
- SELECT: [business_users_role, dev_users_role]
- INSERT: [dev_users_role]
publish_logic:
- branches: [main, staging, migration_dwh]
Example in Y42
In Y42, every UI action, from changing the asset definition to enriching it with metadata info or publishing the asset, is version-controlled and stored as code. For instance, defining a Python ingest source results in the creation of the following yml file:
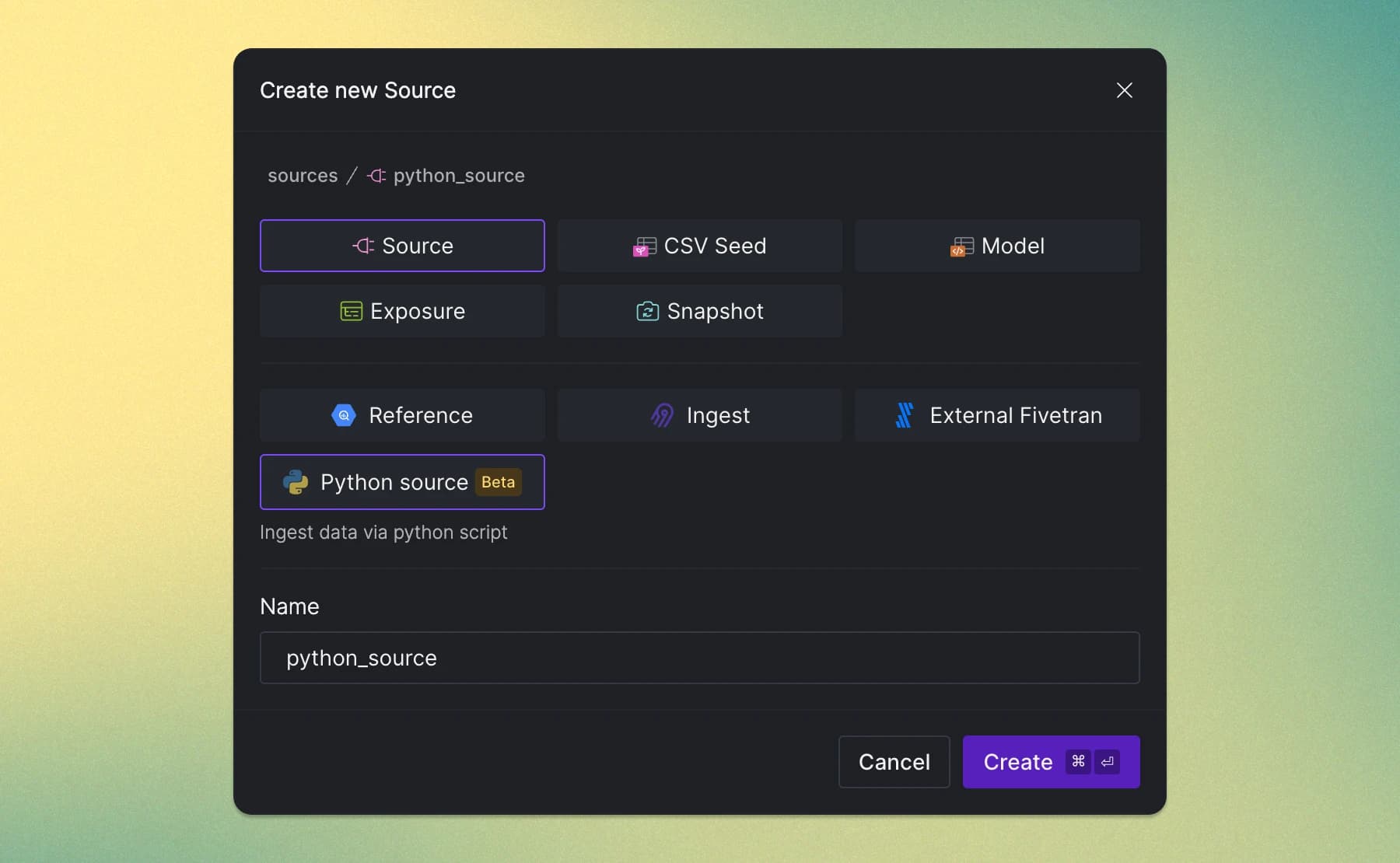
version: 2
sources:
- name: python_source
config:
y42_source:
type: python-ingest
..
The file generated is similar when defining an Airbyte source:
version: 2
sources:
- name: airbyte_source
config:
y42_source:
type: source-gcs
connection: "gcs_data"
The standardization extends to schema inference for source tables and columns:
sources:
- name: python_source
config:
y42_source:
type: python-ingest
meta:
experts:
users:
- octavian.zarzu@y42.com
tables:
- name: products
columns:
- name: product_id
data_type: INTEGER
- name: created_at
data_type: TIMESTAMP
..
When models are added, they configuration is similar:
models:
- name: stg_products
columns:
- name: product_id
data_type: INTEGER
- name: created_at
data_type: TIMESTAMP
..
Implementing tests on a column, like product_id, produces the following metadata:
models:
- name: stg_products
columns:
- name: INTEGER
data_type: STRING
tests:
- uniques
- not_null
- name: created_at
data_type: TIMESTAMP
..
Unpublishing an asset from a branch leads to the same code change for both sources and models:
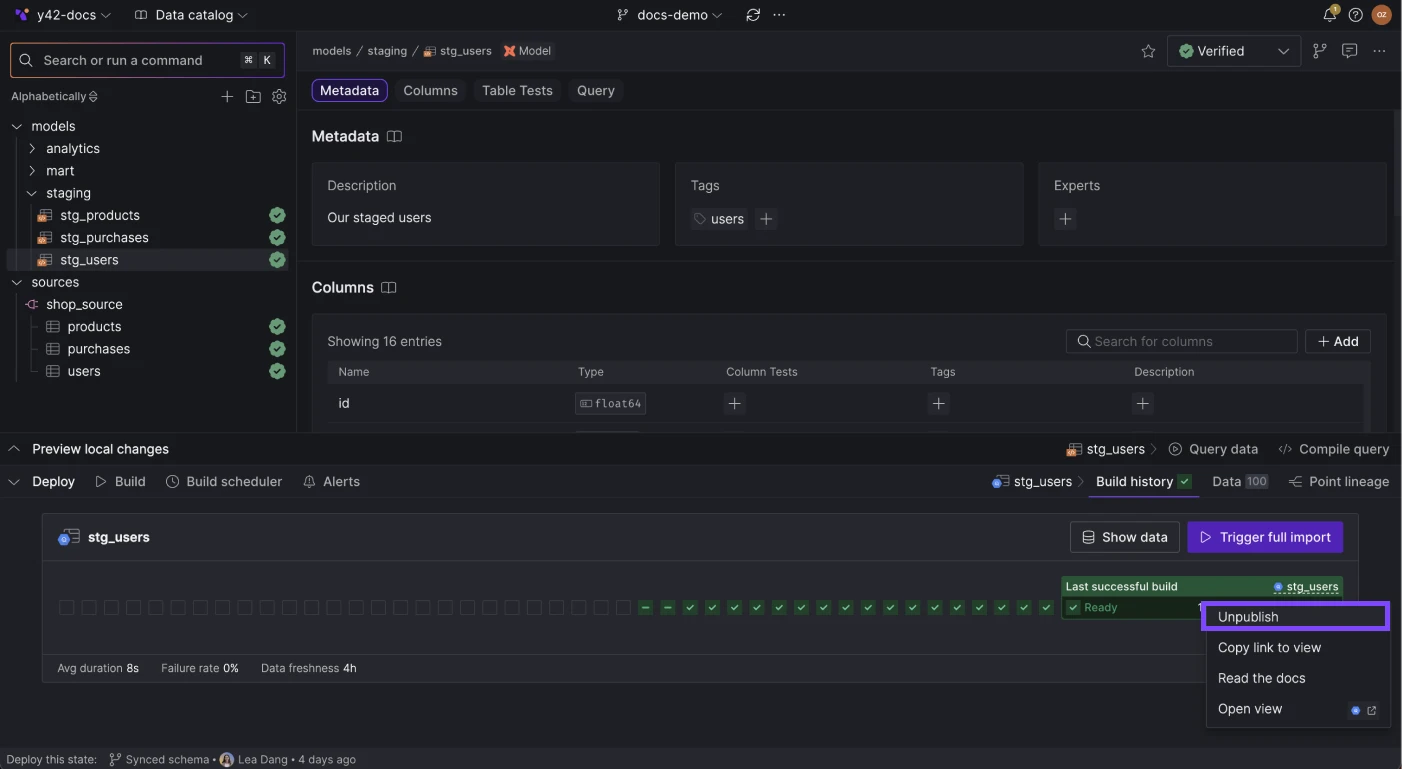
models:
- name: stg_products
config:
y42_table:
publish_view: false
Roles are assigned using the following syntax:
models:
- name: stg_products
config:
grants:
roles/bigquery.dataviewer:
- 'bobby.lecki@acme.com'
- 'jennifer.woo@acme.com'
Subsequently, these permissions are synced with the roles and permissions in your data warehouse.
Stateful Data Assets: Standardization and Lifecycle Management
Y42's approach to Stateful Data Assets centers on the principle of standardization, drawing inspiration from the Liskov substitution principle. We introduce an abstract base class, y42 data asset, as the foundation for subclasses such as dbt model and airbyte source. These subclasses adhere to a standardized interface defined in the base class, despite their unique internal states.
Metadata standardization and upstream dependencies
In our framework, each lifecycle stage of a data asset adds specific functions and methods, building on the outputs of the preceding stages. Generating uniform metadata is key for interoperability and for deriving data lineage across your end to end data stack. Moreover, each asset is linked to its upstream assets via code, which ensures that changes in one asset are propagated to all dependent assets downstream automatically.

The evolution to stateful and declarative methods
Moving toward stateful and declarative methods represents a significant shift in managing data assets. From manual data extraction and transformation processes, we now can leverage a declarative approach where the system knows how to meet user-defined requirements. This transition from imperative tools to a declarative methodology aligns the data stack more closely with the data warehouse by pushing optimized and standardized code. Backed by a stateful approach this grants users the ability to select and revert to any previous asset state or create a new copy of your production data as a separate environment to develop in.
Category
In this article
Share this article
