
We are excited to announce the launch of Python Ingest as the newest type of asset to our platform. With it, you can:
- implement custom ingestion logic
- remove boilerplate code to load data into your data warehouse
- get standardized metadata, lineage, and documentation out of the box.
Python has become the go-to language for data engineers to extract and load data from custom sources — sources that are specific to your organization or are not commonly used so ELT vendors like Fivetran or Airbyte can adopt and create a connector for.
Its popularity stems from its ease of use, simplicity, and readable syntax. Python also benefits from an active community and is well-suited for data analytics, thanks to popular libraries such as Pandas or Polars for data manipulation, NumPy for numerical computations, scikit-learn for machine learning, BeautifulSoup for web scraping, or Seaborn, Bokeh, and Matplotlib for visualization, among others.
While writing Python scripts locally to extract data might seem like a breeze, deploying, managing security, dependencies and infrastructure are not.
Read on to dive deeper into our worldview and how we introduce Python Ingest sources to Y42.
Python Ingest sources as assets: Standardized metadata, lineage and documentation out of the box
At Y42, we treat each object as a stateful data asset:
You can think of a data asset, similar to a river: it changes and evolves over time due to new data coming in, existing data being updated or deleted, and the asset going through its own lifecycle – from developing, testing up to deploying and publishing – or upstream schema changes that have to be propagated downstream. With each such change, a new variation of the asset is materialized in the form of a table in the data warehouse, and new metadata is generated to track all the table snapshots created.
For us, it was important to have Python scripts treated as data assets as well. This allows us to perform zero-copy deployments,rollbacks, protect the production environment integrity by preventing faulty builds from going live, and manage the code and data of an asset together through Git. If you are interested in finding out more about it, you can read about Virtual Data Builds here.
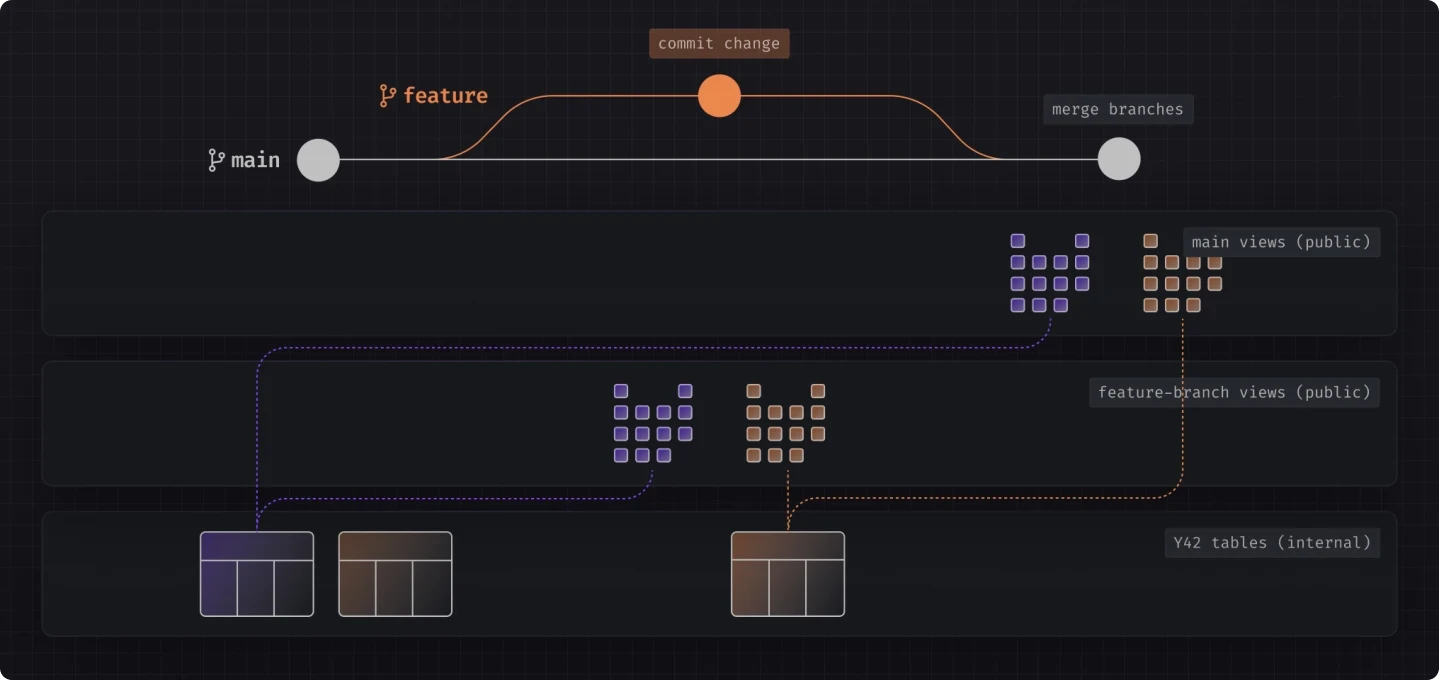
The Virtual Data Builds mechanism introduces a two-layer approach for managing code and data together.
Furthermore, our goal was for Python scripts to be recognized as first-class entities within the (modern) analytics stack, similar to the transformation dbt brought to SQL models. When you create a Python Ingest source asset, two files are automatically generated and ready to be committed: a .py file containing your python script, and a .yml file filled with all the standardized metadata Y42 generates on the fly based on your actions.

YAML files are auto-generated with standardized metadata based on your actions in Y42.
Each Python Ingest source asset can be referenced downstream in a dbt model or a Python action, similar to any other Y42 supported source:
from {{ source('python-asset-name', 'function-table-name') }}
When you reference a Python asset downstream, the column-level lineage is immediately updated to reflect the new link.

The Python Ingest source asset connected to the Python action asset downstream via the source function.
Additionally, you can document, add tests, and tags to Python Ingest source assets in a similar manner to how you would manage any other data assets in Y42, including dbt models.
Focus on the extraction logic only. No boilerplate code to load data into the data warehouse
In Y42, you only need to focus on the logic to extract the data and return it as a DataFrame. Loading your data into your data warehouse is done automatically for every function decorated with @data_loader.
@data_loader
def api_data(context) -> pd.DataFrame:
BASE_URL = 'YOUR_URL'
response = requests.get(url)
data = json.loads(response.content)
df = pd.DataFrame(data)
return df
Tip for handling larger requests: For operations that involve large data requests, we recommend using pagination if possible. Alternatively, consider using
requests.get(url, stream=True)to stream the data. This approach helps in avoiding memory issues by preventing the loading of the entire object into memory at once.
Logs and output data can be previewed for any function that is decorated.

Y42 maintains the state between assets’ runs, so you can also incrementally load data into your data warehouse.
@data_loader
def api_data(context) -> pd.DataFrame:
prev_state = context.state.get()
if prev_state:
last_update = prev_state['last_update']
# perform incremental activities, such as filtering the dataset by last_update variable
else:
# perform full refresh activities
context.state.set({"last_update": datetime.utcnow()})
return df
Secrets can be referenced in your asset's script using the following syntax:
@data_loader
def api_data(context) -> pd.DataFrame: # Add the context argument to your function
api_key = context.secrets.get("api_key") # Get a specific secret by passing its name
all_secrets = context.secrets.all() # Or you can get all the keys as a dictionary.
Serverless execution: No need to manage infrastructure
The Python scripts are executed serverless as Cloud functions– eliminating the need for you to manage infrastructure. We provide two cluster sizes for running functions: S and L. Having Python Ingest source objects recognized as assets, it means you can also execute them alongside other assets using DAG selectors:
y42 build --select source:api_data+
The + selector, when used after the asset name in the command, also triggers all downstream dependencies.

What’s next?
We are committed to making Python more accessible to everyone.
Our journey started with the aim of making data pipelines reliable and making changes to your pipelines with confidence. This led to the creation of the Virtual Data Build mechanism and the deep integration of git, allowing for code and data to be version-controlled together. On this foundation, we developed the Python Ingest source assets.
Recently, we launched a public beta of Python Actions. This feature enables you to synchronize your data pipelines with workflows in tools like Asana, JIRA, Hubspot, or any other tool you prefer. From Reverse ETL into Salesforce to task creation in Asana or sending Slack notifications, you can enjoy a Zapier or Make-like functionality, with centralized processing, and integrated documentation. More information is available in our documentation, including one of the first guides on how to trigger syncs in Hightouch or Census.
Concurrently, we are working on Python Transform assets. Combining Python Ingest sources, Transforms, and Actions enables you to create end to end ML pipelines. These can live alongside your SQL data pipelines and take advantage of the same benefits you got out of the SQL assets in Y42: integrated lineage view, documentation, CI bot, zero-copy deploy, rollbacks, without having to worry about managing infrastructure, defining dependencies outside of your code, or dealing with boilerplate and repetitive code.
Conclusion
Python Ingest source assets provide a simple way to extract and load data from your custom sources. You only need to manage the logic for data extraction. Y42 takes care of loading the data into the warehouse, offers end-to-end visibility through column-level lineage, and provides documentation, similar to any other asset you create in Y42 in a single place. The execution is serverless, and like with any other asset, with Python Ingest source assets, you can version control data and code together through the Virtual Data Build mechanism.
Python Ingest source assets add to the 500+ built-in connectors that Y42 offers. For more information about Python Ingest source assets, you can check our documentation.
Category
In this article
Share this article
