Transform data
Now that we have data to work with, it's time to expand our pipeline with data transformations! In this section, we discuss the different types of assets that exist in pipelines and transform the source assets from section 3 into staging models.
Data transformations
In a pipeline, we apply data transformations to assets, which results in new assets. These resulting assets are called models. For example, we can take two source assets, join them together, and save the result as a model.
Typically, we use the following types of assets to refine data increasingly:
- Source assets: the raw data as we ingest it into your data warehouse
- Staging models: one-to-one relations to source assets, but with basic data cleaning applied (e.g., data types, renaming, reordering, parsing)
- Intermediate models: meaningful combinations of staging models that are useful for data engineering but unsuited for the needs of business users
- Mart models: the final layer that combines intermediate and staging models in a way that can be presented to business users (e.g., through dashboards)
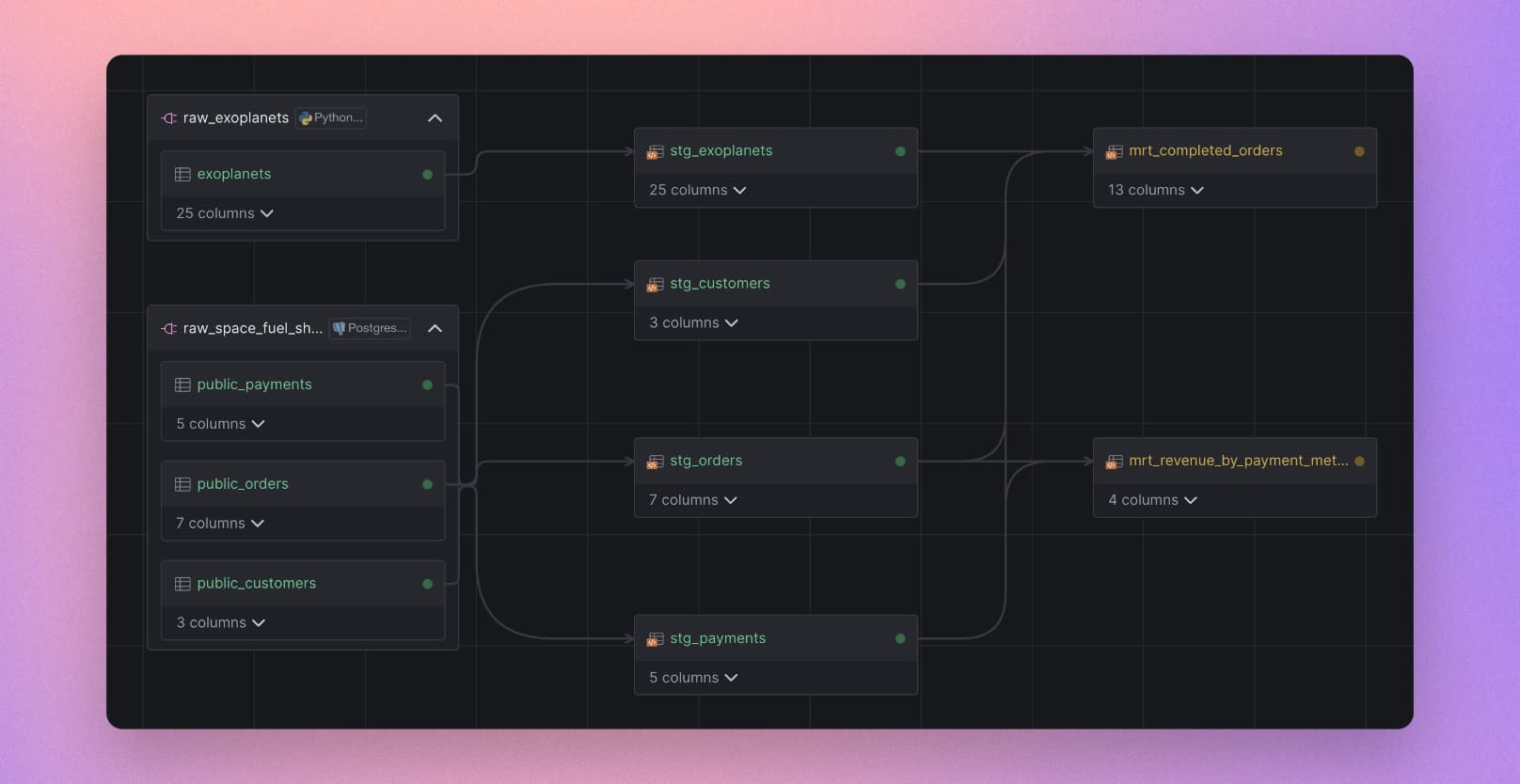
A pipeline based on the source assets from the previous section.
Create a new model
Let's dive straight in and create models that transform our source data. We'll create a stg_orders model that cleans up the raw_orders table.
Add a staging model
- Navigate to the
Listview in the Asset Editor - Press on
📁and create amodelsdirectory with astagingsubdirectory - Press on
+ - Select
Modeland selectmodels/stagingas its path - Name the model:
stg_orders - Insert the following query
- Preview the model by clicking on the
▶️ (Preview query)button at the top left of the SQL editor or by using the hotkey CMD / CTRL + RETURN while having your cursor in the SQL editor. Verify that you can see the renamed columns and the parsedorder_statuscolumn.
Commit & push the changes
In the background, Y42 has automatically created two files: stg_orders.sql and stg_orders.yml. If you navigate to the Code view, you can see the contents of these files. The .sql file contains our query, and the .yml file includes a reference to the query.
Commit and push these changes with an appropriate commit title (e.g., model: add stg_orders model)
Build the model
- Click on the table in the left file selector
- Open the bottom drawer
- Navigate to
Build - You should see a pre-defined build command. If not, enter
y42 build -s stg_orders - Click on
Build now - Observe the build job and wait for the job to be
Ready
Add metadata to the model and preview data
- Click on
Sync columns, which will add the following columns:_10order_id_10customer_id_10fulfillment_method_10line_items_10service_station_10order_status_10order_received - Commit and push the table metadata with an appropriate commit title (e.g.,
meta: add stg_orders schema)
Add test for order_status column
Because we applied a transformation to the order_status column, let's write an extra test for that column.
- Click on
+in theColumn Testscolumn for theorder_statusrow. - Select
Accepted valuesas a test type - Enter the values from the query above:
CANCELLED,DECLINED, andACCEPTED - Commit and push these changes with an appropriate commit title (e.g.,
test: add accepted_values test for order_status column)
From here, you can also transform the other source tables into staging models and add all of the appropriate metadata.
Up next
Outstanding! We've added the stg_orders model that contains the transformation logic for our data pipeline. Next, we'll create an orchestration to schedule the pipeline.